
Artificial intelligence
4 Application of artificial intelligence in nystagmus analysis
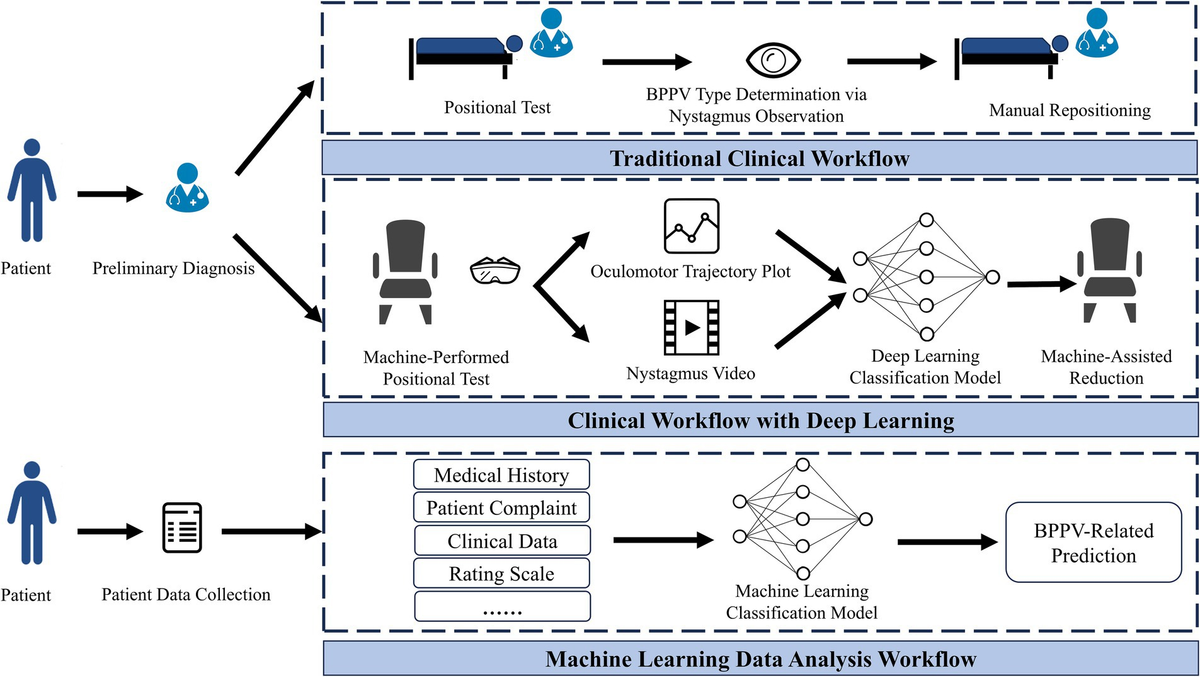
Nystagmus refers to the involuntary, rhythmic, reciprocating movement of the eyes when fixing gaze on a specific point. Based on the direction of this rhythmic oscillation, nystagmus can be classified into horizontal nystagmus, vertical nystagmus, and torsional nystagmus. In clinical diagnosis, the core diagnostic criterion for BPPV is the nystagmus manifestations observed during a patient’s vertigo episode. The types of nystagmus induced by BPPV mainly include horizontal nystagmus and vertical upbeat nystagmus with a torsional component. Currently, the standard clinical tool for data acquisition is the head-mounted video oculography system. This device incorporates infrared cameras, infrared light-emitting diodes, and goggle assemblies to enable accurate capture of dynamic eye movement videos. In AI-assisted BPPV diagnostic research, the accurate localization of the ocular region serves as an indispensable core prerequisite and fundamental step.
Rodrigues et al. (15) proposed the At-UNet neural network model, which adopts VGG16 as its backbone encoder. By integrating an attention module and a multi-task learning framework, the model achieves simultaneous and accurate segmentation of the pupillary region, yielding a Dice coefficient of 96.20% for pupil segmentation on the UTIRIS dataset. However, the model suffers from a large number of parameters, which hinders its lightweight deployment in clinical settings. Wei et al. (16) combined the YOLOv5 object detection network with an improved DeepLabv3 + segmentation module; precise pupillary coordinates were obtained via ellipse fitting of segmentation masks, with the final intersection over union (IoU) reaching 95.95%. While this approach is well-suited for real-time clinical requirements, the ellipse fitting method exhibits poor adaptability to pathologically irregular pupils and is thus prone to generating deviations.
Ideal acquisition of patients’ ocular information is often hindered by various interferences. Cho et al. (17) developed a lightweight multi-task model that integrates a blink detection module into the pipeline of pupil localization and tracking, which specifically addresses invalid frames caused by eye blinking; the model achieved IoU values of 92.81 and 90.73% on the OpenEDS and HUSHH datasets, respectively. While well-suited for dynamic clinical scenarios and characterized by low deployment barriers, this multi-task architecture leads to slightly reduced precision in individual tasks, and its sensitivity to the recognition of rapid consecutive eye blinks requires further improvement. To evaluate the performance of pupil segmentation algorithms under different noise conditions, Ju-Hyuck et al. (18) proposed a combined RANSAC+U-Net scheme. Results showed that the RANSAC+U-Net combined algorithm performed optimally in the noise-free scenario with a mean squared error (MSE) of 0.0620; the standalone U-Net algorithm excelled in the optical noise scenario with an MSE of 0.0694; and the standalone RANSAC algorithm yielded the best performance in the motion blur noise scenario with an MSE of 0.0717. However, all algorithms exhibited poor performance in the presence of human-induced noise, such as occlusion by eyelids and eyelashes. The core underlying reason is the lack of critical image features, coupled with the absence of effective feature completion mechanisms in existing models, which renders them unable to accommodate the variability of complex physiological structures.
Choi et al. (19) proposed an automatic eyeglass removal method based on the CycleGAN network. The primary objective of a generative adversarial network is to use a discriminator to calculate the distribution of original samples, while a generator works to generate new samples from real data samples (20). This method is applied to supplement the key information of the ocular region that is lost due to the presence of eyeglasses. In future research, we can also explore solutions to problems such as data loss and noise interference in pupil localization by leveraging generative adversarial networks.
In summary, compared with the iris, the pupil offers the advantages of high stability, strong anti-interference capability, and low algorithm complexity, making it more suitable for meeting the technical requirements of nystagmus video analysis and aligning with the core clinical diagnostic demands of speed, real-time performance, and anti-interference capability. Although artificial intelligence is currently capable of pupil localization and tracking, there remains significant room for optimization in numerous aspects.
The ocular movement trajectory plot converts subjectively observable nystagmus into objectively quantifiable trajectory curves and data, thus avoiding deviations caused by manual judgment. To address the challenge of accurate pupil tracking, Lee et al. (21) developed ANyEye, an AI-assisted nystagmus video analysis system that integrates a compensation algorithm to correct pupil positions, achieving a detection rate of 91.26% for pupil tracking within a 5-pixel error margin, making it well-suited for dynamic clinical tracking applications. However, its adaptability to high-velocity nystagmus scenarios was not reported in the study. Deng et al. (22) proposed the lower pole of pupil algorithm and employed ResNet34 for classifying four common subtypes, with the accuracy rate reaching 95.55%. Regarding the issue of data loss caused by pupil occlusion due to various factors, Mun et al. (23) pointed out that linear interpolation, if adopted as a missing data bridging algorithm, might inadvertently generate nystagmus-like motion artifacts; filling missing values with the pupil position detected at the previous moment (denoted as NA) yields better results. Ultimately, the CNN1D model was used, achieving an accuracy rate of 91.02%. This approach provides a quantitative reference for missing data handling, though its effectiveness in scenarios involving prolonged pupil occlusion remains to be verified.
Due to the limited information that can be conveyed by a single trajectory plot, many researchers have begun to explore converting trajectory plots into other forms of information for nystagmus identification. Dogru et al. (24) transformed the original trajectories into polar coordinates and calculated angular changes via template matching, successfully addressing the challenge of torsional nystagmus detection. Qiu et al. (25) completed classification after converting trajectories into Gram matrix feature images, achieving a Top-1 accuracy of 85.47%. Lee et al. (26) utilized the wavelet transform to convert time-series signals into time-frequency images, which were ultimately fed into the EfficientNet convolutional neural network for classification, yielding an overall accuracy of 87%. Although different data conversion strategies can improve the accuracy of nystagmus identification from specific dimensions, such transformation processes are often associated with several limitations. These drawbacks include the easy loss of temporal information during feature mapping and the lack of unified criteria for wavelet transform parameter settings, which exert a notable impact on the final results.
In addition, the adoption of a multimodal approach that incorporates more clinical information for analysis can improve diagnostic accuracy. Wu et al. (27) converted eight features, including head trajectory, eye movement trajectory, and their corresponding slow-phase velocity values, into 1D data as input. Nguyen et al. (28) fused five-channel time-series data consisting of horizontal eye movement, vertical eye movement, pupil radius, horizontal velocity, and vertical velocity. Going beyond nystagmus-related information alone, Liu et al. (29) adopted a multi-technology fusion strategy combining image features and signal analysis to conduct comprehensive nystagmus detection. Although such multimodal fusion methods can significantly enhance the generalization ability of models in clinical settings, they inevitably increase model complexity, thereby raising the bar for clinical deployment and implementation.
In clinical practice, physicians still rely primarily on the direct interpretation of eye movement images as the main diagnostic basis, and ocular movement trajectory plots have not yet become routine core diagnostic tools. Notably, current intelligent classification research on BPPV based on ocular movement trajectories has demonstrated significant clinical effectiveness and promising application prospects.
With the gradual emergence of intelligent video analysis technology as a research hotspot in the field, relevant research directions have also begun to focus on nystagmus video analysis, which serves as the core carrier for clinical diagnosis. Li et al. (30, 31) designed different deep learning algorithms integrating multiple modules for vertical nystagmus and torsional nystagmus, achieving an accuracy of 91 and 96.1%, respectively. However, the adaptability of these algorithms to complex clinical scenarios in practical experiments remains to be verified. Lim et al. (32) developed a 2D-CNN model that converts the 3D eye movement features in videos into grid images for classification. Results showed that the area under the curve (AUC) for horizontal nystagmus and vertical nystagmus reached 0.966 and 0.952, respectively, while the AUC for torsional nystagmus was only 0.853. The main limitation lies in the fact that the identification of torsional nystagmus relies on the accurate capture of iris rotation states. In clinical infrared videos, low brightness and contrast often blur iris textures, impeding feature extraction.
To address the problem of limited recognition accuracy for torsional nystagmus, researchers have introduced optical flow technology. The core principle of optical flow is to estimate pixel displacement between consecutive video frames for accurate capture of motion dynamics (33). Kong et al. (34) used LiteFlowNet to extract optical flow features, which were then fused and classified via the nystagmus video classification network based on temporal modeling. This method achieved an F1-score of 0.98 for torsional nystagmus, surpassing the 0.928 score obtained for non-torsional nystagmus. Zhang et al. (35) proposed a Torsion-aware Bi-Stream Identification Network, which inputs optical flow in the x and y directions into the two-stream network for torsional nystagmus recognition, reaching an accuracy of 85.73% in clinical evaluations. Model designs incorporating optical flow fields are more compatible with the characteristics of clinical videos, effectively resolving the recognition challenges caused by blurred iris textures. Nevertheless, optical flow feature extraction imposes certain computational requirements, which may increase the costs associated with clinical deployment.
In addition to optical flow features, conducting multimodal fusion research that incorporates the multidimensional clinical characteristics of vertigo associated with BPPV can also effectively improve the diagnostic accuracy of the model. Lu et al. (36) encoded head position vectors using an autoencoder to capture spatial information, and fused the encoded information with video features via a cross-attention mechanism, achieving an average accuracy of 81.7%. While this approach enabled the synergistic utilization of head posture and eye movement information, it suffered from the drawback of high computational complexity during the feature fusion process. Pham et al. (37) developed a hybrid deep learning system named “Look and Diagnose”, which integrates body posture and binocular vision information. The system first detects posterior semicircular canal BPPV and then classifies non-posterior semicircular canal otolithiasis, with an overall classification accuracy of 91% and demonstrating strong alignment with clinical diagnostic workflows. Table 1 systematically presents the research on deep learning related to nystagmus video analysis. These studies indicate that deep learning has currently achieved favorable results in the clinical image analysis of BPPV and can provide references for clinical practice. Nevertheless, continuous optimizations are still required in terms of computational cost control, generalization capability in complex scenarios, and adaptability to clinical workflows.
Summary of deep learning research related to nystagmus analysis.
Related Stories
 AI News
AI News
Man Utd news: How are World Cup stars faring?
1 minute ago
 AI News
AI News
Robotic elephants are replacing live ones at Kerala temple festivals, in photos
2 minutes ago
 AI News
AI News
Did the World Cup pay off? New data raises questions about economic boost
2 minutes ago
 AI News
AI News
Hundreds in Kelowna watch as Portugal beats Croatia in nail
2 minutes ago
 AI News
AI News
‘Ridiculous’ for US to maintain current Nato support, Trump warns ahead of alliance summit
2 minutes ago
 AI News
AI News
Meta says WhatsApp usernames are safeguarded against scams after India flags cybersecurity risks
3 minutes ago
 AI News
AI News
India news: Indian delegation leaves for Khamenei's funeral
3 minutes ago
 AI News
AI News
Metallica to help 1,000 London college students
3 minutes ago